Peter Brödner
›Autonome‹ Systeme, die keine sind – wie uns Propagandisten ›künstlicher Intelligenz‹ in die Irre führen
›Autonome‹ Systeme, die keine sind –
wie uns Propagandisten ›künstlicher Intelligenz‹ in die Irre führen[1]
Wieder einmal überrollt uns eine Sturzflut von Meldungen über Projekte vermeintlicher ›künstlicher Intelligenz‹ (KI, engl. AI für ›artificial intelligence‹). Die Spannweite reicht von Heilsversprechen über Erfolgsgeschichten bis zu Szenarien der Apokalypse:
- Über die künftige ›smarte‹ Automobilfabrik heißt es etwa: »Superschlaue Computer, die ständig lernen, werden vieles übernehmen, was bisher Menschen erledigen: Sie antworten, wenn Kunden oder Lieferanten fragen, automatisch [...] [S]ie entwerfen sogar Autos und rechnen aus, wie sich die Entwürfe in der Fabrik umsetzen lassen.«,
- »Lernende Maschinen erkennen Gesichter und bringen sich selbst das Schachspielen bei.«
- Hawking fürchtet, dass »KI Menschen komplett ersetzen könnte« in einer »neuen Lebensform, in der Menschen unterlegen wären«.
Bei solch atemberaubenden Äußerungen hilft nur, nüchtern die Wahrheit in relevanten Tatsachen zu suchen. Freilich beginnen die Schweirigkeiten schon damit, dass ›KI‹-Systeme begrifflich nicht von ›gewöhnlichen‹ Computersystemen zu unterscheiden sind: Auch letztere wurden immer schon zur Bewältigung von Aufgaben geschaffen »die nach landläufiger Auffassung Intelligenz erfordern« (wie übliche ›KI‹-Definitionen lauten). In jedem Fall führen Computersysteme berechenbare Funktionen zur automatischen zweckmäßigen Verarbeitung zugehöriger Daten aus – und nichts sonst.
Zudem zeugt die Fokussierung auf technische Artefakte und ihre Eigenschaften von einem tiefen Missverständnis von Technik. Als »Anstrengung, Anstrengungen zu ersparen« (Ortega y Gasset) umfasst Technik über die bloße Ansammlung technischer Artefakte hinaus stets auch deren sozial konstruierte und kulturell vermittelte Herstellung und Anwendung im Spannungsfeld des technisch Machbaren und des sozial Wünschenswerten, abhängig von jeweils herrschenden Interessen. Artefakte fallen nicht vom Himmel, sondern müssen für bestimmte Zwecke mühsam konzeptionell entwickelt und materiell hergestellt werden. Als solche sind sie aber bloß tote, nutzlose Gegenstände, solange sie nicht für bestimmte Aufgaben zweckgemäß angeeignet und praktisch wirksam verwendet werden.
Die Irrtümer des ›KI‹-Diskurses zu erkennen, erfordert indes nichts weiter als die tatsächliche Funktionsweise fortgeschrittener Computersysteme sowie deren Entwicklungs- und Anwendungsprobleme in den Blick zu nehmen, hier am Beispiel ›künstlicher neuronaler Netze‹ (KNN) und Verfahren des ›Deep Learning‹, die derzeit als vermeintliche Schlüsseltechnik der ›KI‹ besonders hoch im Kurs stehen.
Funktionsweise prominenter ›KI‹-Systeme
Ein KNN besteht im Wesentlichen aus einer Menge miteinander verbundener Knoten j, die in Abhängigkeit von ihrem aktuellen Aktivierungszustand und der momentanen Eingabe ihren neuen Zustand bestimmen und eine Ausgabe produzieren. Die Knoten sind gemäß der Netzwerkstruktur, dargestellt durch einen Graphen oder eine Konnektionsmatrix, miteinander verknüpft. Die Dynamik eines KNN wird beschrieben durch (vgl. Abb.):
- eine Propagierungs- bzw. Übertragungsfunktion netj, die aus den Ausgaben der vorgeschalteten Elemente sowie der Gewichtung der Verbindungen die aktuellen Eingaben in interne Netzwerkelemente berechnet,
- eine Aktivierungsfunktion σ, die für jedes Element dessen Aktivierung oj als Ausgabe bestimmt abhängig davon, ob ein Schwellwert von der Netzeingabe netj überschritten wird oder nicht.
Abb.: Berechnungsfunktionen an einem Netzknoten
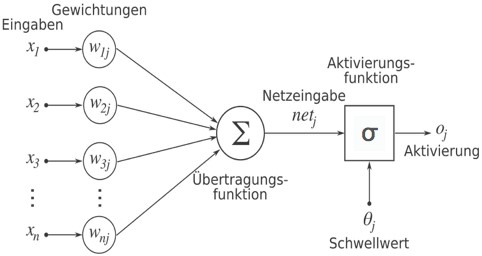
In der Regel besteht die Propagierungsfunktion aus einer einfachen Summenbildung der gewichteten Verbindungseinflüsse und die Aktivierungsfunktion wird meist für alle Elemente des Netzwerks einheitlich festgelegt. Innerhalb eines Netzwerks wird noch zwischen Eingabe-, Ausgabe- und internen Elementen unterschieden (›hidden units‹, die zu tief gestaffelten ›hidden layers‹ zusammengefasst werden, daher die Bezeichnung ›Deep Learning‹). Mittels verschiedener Typen von Ausgabe-, Propagierungs- und Aktivierungsfunktionen können Klassen von konnektionistischen Modellen gebildet werden.
Zur Lösung ihrer Aufgaben müssen KNN während des Entwurfs passend strukturiert und ihre Gewichte algorithmisch gesteuert mittels der Eingabedaten trainiert werden. Das Netz wird darüber hinaus nicht programmiert, sondern passt sich durch Veränderung der Gewichte nach Maßgabe eines den Nutzen maximierenden ›Lern‹-Algorithmus an die spezielle Aufgabenstellung an (daher auch die Benennung adaptiv). Beispielsweise werden bei Problemen der Klassifikation oder der Musteridentifikation – ein Aufgabentyp, bei dem KNN, vor allem sog. ›faltende‹ oder ›Convolutional Neural Networks (CNN)‹, besonders leistungsfähig sind – einer langen Reihe von Eingabemustern jeweils die zugehörigen Klassen als Ausgänge zugeordnet; aus diesen Zuordnungen vermag dann der Algorithmus mittels einer Nutzenfunktion automatisch passende Verbindungsgewichte zu bestimmen. Dies funktioniert auch bei Mustern, die durch explizite Merkmalsbeschreibungen schwierig oder gar nicht zu fassen sind (etwa bei der Identifikation von Gesichtern oder handgeschriebenen Buchstaben) – freilich mit Unsicherheiten. Dafür ist meist eine sehr große Zahl von Trainingsbeispielen (in der Größenordnung von 106) erforderlich.
So muss zur Anpassung der Gewichte Wj := Wj – η ????W L eines KNN der Gradient
????W L(N(x)) einer Nutzen- oder Verlustfunktion L(N(x)) berechnet werden (mit N(x) als Netzwerksausgabe und der »Lernrate« η). Die Bestimmung des Gradienten von L erfordert die Bildung der Ableitung von N(x) als Verkettung mehrerer Funktionen nach der Kettenregel. Dabei wiederholt auftretende Faktoren sind während des Trainings oft < 1, sodass das Ergebnis infolge ihrer Multiplikation gegen Null tendiert – daher der »schwindende Gradient« und die Schwierigkeit, vielschichtige KNN zu trainieren. Zudem ist es schwierig, bei der Suche nach den Extremwerten der Nutzenfunktion eine variable, situativ passende Schrittweitensteuerung zu realisieren.
Diese praktischen Schwierigkeiten bei der Strukturierung wie beim Training der Netzwerke sind nur durch jeweils fallspezifische Kunstgriffe zu überwinden, die das Können ihrer Entwickler herausfordern, zumal es für die Gestaltung der KNN keine theoretisch fundierten Erkenntnisse gibt. Folglich müssen für jede Aufgabe passende Netzwerkstrukturen und Nutzenfunktionen mühsam mit großem Trainingsaufwand und ohne Erfolgsgarantie ausprobiert werden. Die Performanz der Netzwerke verdankt sich daher allein der Erfahrung, dem Können und der Kreativität ihrer Entwickler, darüber hinaus auch der exponentiell gesteigerten Leistungsfähigkeit von Computer-Hardware. Zudem sind KNN in hohem Maße störanfällig. Schon durch geringfügige Veränderung eingegebener Daten können sie in ihrer Funktionstüchtigkeit stark beeinträchtigt werden. So gibt es denn auch vielfältige Fehlleistungen von ansonsten erfolgreichen KNN und zahlreiche Beispiele sind belegt etwa bei der Bild-Klassifikation.
In letzter Zeit hat das System AlphaGo von Deep Mind (sic!) viel Aufsehen erregt, das in Turnieren die weltbesten Go-Spieler zu schlagen vermochte. Es wird häufig als der ultimative Nachweis von dem Menschen überlegener ›künstlicher Intelligenz‹ und ›maschinellem Lernen‹ präsentiert (obgleich dessen Funktionsweise mit Lernen im eigentlichen Sinn nichts zu tun hat). Bei genauerem Hinsehen zeigt sich auch hier, dass diese Behauptungen auf dem propagandistischen Treibsand falscher Zuschreibungen gebaut sind.
Zunächst ist festzustellen, dass das Go-Spiel ein mathematisches Objekt ist, das durch seine Regeln vollständig definiert ist. Infolgedessen lässt sich in jeder Stellung eines beliebigen Spielverlaufs eindeutig entscheiden, ob ein Spielzug erlaubt ist oder nicht. Im Prinzip ließe sich daher auch der Baum aller möglichen erlaubten Spielzüge und -verläufe darstellen (was freilich wegen sog. ›kombinatorischer Explosion‹, hier der gigantischen Zahl von geschätzt rd. 200150 Zweigen, physisch unmöglich ist; es handelt sich um ein NP-vollständiges Problem).
Mittels heuristischer Verfahren muss daher die Suche nach erfolgreichen Spielzügen und einem möglichst optimalen Spielverlauf auf aussichtsreiche Teilbäume beschränkt werden. Als Methode bewährt hat sich bei vergleichbaren Aufgabenstellungen die Monte Carlo Tree Search (MCTS), die auch hier als heuristischer Verfahrens-Baustein genutzt wird. Dabei werden für Folgezüge einer betrachteten Stellung Erfolgshäufigkeiten – als Verhältnis der Anzahl gewonnener zur Anzahl der insgesamt über diesen Zweig vollzogenen Spiele – mit Hilfe von parallel durchgängig simulierten Zufallspartien ermittelt, die laufend fortgeschrieben werden. Im Falle von AlphaGo wurden dazu auf 40 parallel arbeitenden Prozessoren jeweils 103 Simulationen je Sekunde durchgeführt (was in einer Minute Bedenkzeit zwischen den Zügen maximal 2,4 Mio. Simulationen pro Zug ermöglicht).
In ihrer Leistung gesteigert wird die MCTS noch durch Kombination mit zwei im Spiel gegen sich selbst trainierten neuronalen Netzen, die im Spielverlauf asynchron zusätzliche Bewertungen zur Zugwahl (»policy«, in Form einer über die Zweige verteilten Erfolgswahrscheinlichkeit) und zur Stellung (»value«, als relativem Wert des zugehörigen Teilbaums) ermitteln. Dabei wächst der betrachtete Teilbaum aussichtsreicher Spielzüge durch Einführung neuer Knoten in besonders erfolgversprechenden Zweigen mit anfangs geschätzten Bewertungsgrößen. Diese werden im Zuge der parallel und asynchron durchgeführten Läufe der MCTS-Simulationen und der Wertbestimmung für Zugwahl und Stellungen durch die neuronalen Netze fortgeschrieben, sobald sie verfügbar sind.
Als mathematische, durch Regeln vollständig definierte Objekte sind Spiele entgegen landläufiger Auffassung geradezu prädestiniert für strenge Modellierung und Formalisierung ihrer Spielverläufe. Es ist daher immer schon a priori sicher, dass es Algorithmen geben muss, die menschlichen Spielern überlegen sind. Dass sie erst jetzt gefunden wurden, erklärt sich aus der jetzt erst verfügbaren methodischen Erfahrung und notwendigem mathematischen Können sowie hinreichender Rechenleistung.
Allgemein gilt für ›KI‹-Systeme weiterhin: Grob irreführend als ›künstlich intelligent‹ oder ›lernfähig‹ bezeichnete, de facto lediglich adaptive Computersysteme sind stets und ausschließlich das Ergebnis methodischer Kompetenz menschlicher Experten, deren Können und natürliche Intelligenz sie in Gestalt theoretischer Einsichten in zugrunde liegende Prozesse und raffiniert ausgeklügelter heuristischer Verfahren vergegenständlichen. Das gilt freilich für technische Artefakte, gleich welcher Komplexität, schon immer.
Probleme der Anwendung adaptiver Systeme
Neben Herausforderungen und Schwierigkeiten der Entwicklung adaptiver Computersysteme bestehen aber auch auf Seiten der Anwendung große, wegen ihrer Besonderheit über den Einsatz herkömmlicher Systeme hinausweisende Probleme sowohl epistemischer wie ethischer Natur: Infolge analytischer Intransparenz ist das Verhalten von ›KI‹-Algorithmen (hier v.a. KNN und Verfahren schließender Statistik) selbst für Entwickler faktisch weder im einzelnen durchschaubar (»inconclusive evidence«) noch im Nachhinein erklärbar (»inscrutable evidence«). Sie produzieren nur wahrscheinliche, daher stets unsichere Ergebnisse, deren Korrektheit und Validität von außen nur schwer zu beurteilen sind. Zudem sind KNN sehr störanfällig und leicht auszutricksen. Die Ergebnisse, die sie liefern, sind in hohem Maße von der Qualität der Eingabedaten abhängig, die aber meist ebenfalls unbekannt oder nur schwer einschätzbar ist (»misguided evidence«).
Nutzer können dem Verhalten und seinen Ergebnissen daher nur blind vertrauen – trotz der nicht aufhebbaren Unsicherheit. Das stellt sie in der »Koaktion« mit solchen Systemen vor beträchtliche Belastungen: Wie sollen sie sich solche adaptiven Systeme überhaupt aneignen, wie mit ihnen zweckmäßig und zielgerichtet koagieren, wenn diese sich in vergleichbaren Situationen jeweils anders und unerwartet verhalten? Das wäre ein eklatanter Verstoß gegen eine der Grundregeln der Mensch-Maschine-Interaktion, gegen die Forderung nach erwartungskonformem Verhalten. Zugleich würden, wie oben gezeigt, seitens der Nutzer stets aufs Neue überzogene Erwartungen an die vermeintliche Leistungsfähigkeit der Systeme geschürt, mithin gar ihre Wahrnehmung der Wirklichkeit verändert (»transformative effects«). Konfrontiert mit diesen Widersprüchen, unter dem Erwartungsdruck erfolgreicher Bewältigung ihrer Aufgaben einerseits und angesichts des Verlusts der Kontrolle über Arbeitsmittel mit undurchschaubarem Verhalten andererseits, würden sie unter dauerhaften psychischen Belastungen zu leiden haben. Vordringlich zu fordern ist daher, dass diese Systeme ihre Ergebnisse auf Verlangen nachvollziehbar zu erklären vermögen, was aber bislang nicht einmal ansatzweise gelingt.
Fazit
Die von der ›KI‹ als ›autonom‹ bezeichneten Systeme bestimmen die Regeln ihres Verhaltens nicht selbst, mithin sind sie faktisch nicht autonom, sondern als adaptive Automaten konstruiert. Auch haben Verfahren ›maschinellen Lernens‹ nichts mit Lernen im eigentlichen Sinn zu tun; mathematisch geht es dabei um algorithmisch gesteuerte Funktionsapproximation an gegebene Daten. Zudem ist hinsichtlich der Leistung von AlphaGo festzustellen, dass aufgrund der Regel-Natur von Spielen als mathematischem Objekt Algorithmen menschliche Spieler stets übertreffen können – passende Heuristik und hinreichende Leistung der Hardware vorausgesetzt. Aus dieser Besonderheit kann aber nicht allgemein auf die Überlegenheit maschineller Verfahren über menschliche kognitive Kompetenz geschlossen werden.
Die Irrtümer des ›KI‹-Diskurses lassen den Kern der Sache übersehen: Menschlicher Kreativität gelingt es immer wieder, für spezielle, auch schwierige kognitive Aufgaben algorithmische Lösungsverfahren zu finden und als adaptive Automaten zu realisieren, die aber nur sehr begrenzt auf andere Aufgaben übertragbar sind. Meist ist die aufwendige Entwicklung jeweils eigener Methoden erforderlich, oft mit mehr Aufwand als Nutzen. Sog. ›KI‹-Verfahren sind daher keine »General Purpose Technology«, wie das leichtfertig behauptet wird.
Statt auf illusionäre ›KI‹-Hoffnungen zu setzen, erscheint es angesichts dieser Einsichten weit aussichtsreicher, höhere Flexibilität, Produktivität und Innovationsfähigkeit stattdessen durch soziotechnische Gestaltung »guter Arbeit« zu erreichen. Für diese der ›KI‹ entgegengesetzte Perspektive unterstützender ›Intelligenzverstärkung‹ notwendiges Wissen ist aus über drei Jahrzehnten Forschung zur Gestaltung von Arbeit und Technik verfügbar. Beispielsweise kann eine methodisch angemessene, mittels Selbsterklärung nachvollziehbare Analyse umfangreicher Produktionsdaten genutzt werden für
- interaktive Asssistenzsysteme etwa in der Qualitätssicherung oder Instandhaltung,
- gebrauchstauglich gestaltete Hilfsmittel zur Optimierung von Prozessen,
- die Diagnose komplexer Anlagen,
- die effektive Simulation zwecks optimaler Steuerung von Prozessen.
[1] Der Text ist eine stark gekürzte Fassung meines Beitrags zum Buch »Autonome Systeme und Arbeit«, hg. von Hartmut Hirsch-Kreinsen und Anemari Karačić, das auch als Open-Access-Publikation verfügbar ist. Dort finden sich weitere detaillerte Erläuterungen der Funktionsweise von Systemen und die Belege für die vorliegende Darstellung.